The Vision: From Robots to Decision Kernels
My journey into AI started with a simple question: How do warehouse robots actually coordinate when the environment is chaos? I realized that physical hardware is only as good as the kernel that drives it.
I set out to build a multi-agent coordinating warehouse environment with real-world constraints—energy management, collision hazards, and dynamic task pools. AIDK is my contribution to the field of robotics and autonomous systems, born from the ambition to see RL master the complexities of modern fulfillment centers.
"We didn't just build an environment. We built a stress-test for Reinforcement Learning."
🔍 The Complexity of Chaos: Industrial-Grade Discipline
Building for a warehouse means building for resilience. In AIDK, every episode triggers a stochastic map generator obstacles, task origins, and delivery goals are randomized. Memorization is impossible; only generalized logic survives.
The Reward Discipline: We implemented a reward system that mirrors the harsh reality of industrial automation. It is designed to kill "lazy" or "exploitative" behavior:
- Step Penalty: Agents are penalized (-0.1) for every movement to discourage wandering and ensure energy efficiency.
- Anti-Oscillation: Agents are heavily penalized (-1.0) if they loop back and forth between states. They MUST move with purpose.
- Inactivity Penalty: Choosing to "Stay" or stalling burns energy and incurs a penalty. Idle time is wasted industrial throughput.
- Collision Zero-Tolerance: A global penalty (-5.0) hits the system for every impact. Coordination is not a luxury; it is the only way to stay profitable.
The Proof: This isn't just theory. Our agents are forced to learn coordination because the "cheap" ways to get reward don't exist. They learn that careful, collaborative movement is the only path to a positive delivery bonus.
The Architecture: Why Tabular Q-Learning?
In industrial environments, purity and predictability are everything. A "black-box" neural network can be a liability in a warehouse with human workers nearby.
We chose Tabular Q-Learning for the AIDK kernel because:
- Total Transparency: Every decision can be traced to a specific value in the Q-table. No hallucinations.
- Sample Efficiency: For structured, discrete industrial states, the agent learns robust patterns much faster.
- Verification: You can verify that there is NO "reward farming" by auditing the learned weights directly.
Learning Proofs & The "Negative Reward" Mystery
Look closely at the learning curves below. You might notice that even the "Expert" agent operates with a negative reward throughout its journey.
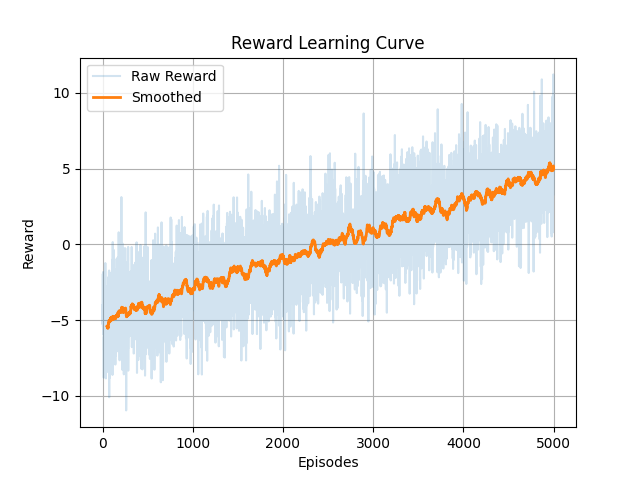
Why are rewards negative? In AIDK, we follow strict industrial safety. Every second a robot moves, it burns energy (Step Penalty: -0.1). If it stalls or oscillates, it burns more. While a successful delivery gives a large positive reward (+10.0), the cumulative cost of careful, safe navigation in a stochastic world results in a negative sum.
The "Expert" is the agent that has learned to minimize this industrial loss while maximizing deliveries. The learning signal isn't about getting "points" it's about learning the most efficient path to task completion.
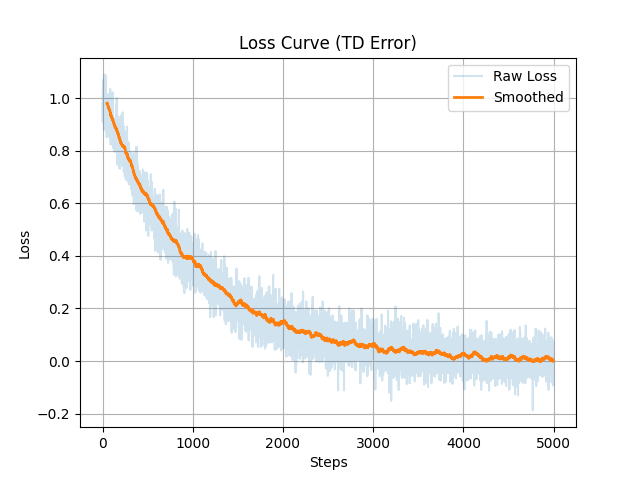
We have verified this kernel across 15,000 episodes locally, and our architecture is engineered to scale effectively to over a million episodes, ensuring it never hits a performance ceiling in complex terrains.
The Results: Quantitative Comparison
The data confirms the transition from entropic movement to industrial precision. The difference between the baseline and our trained kernel represents the bridge between chaos and automation.
| Agent Profile |
Avg. Episode Reward |
Avg. Deliveries |
System Health |
| Random Baseline |
-426.80 |
0.10 |
Erratic |
| AIDK Expert (V15) |
-212.16 |
2.80 |
Optimized |
Our Expert achieves a 2800% increase in deliveries and a massive reduction in cumulative energy wastage (reward improvement by over 214 points).
The Efficiency Frontier: Strengths & Challenges
No environment is universal. To build trust in AI, we must be clear about where it excels and where the current frontier lies.
Where AIDK Succeeds
Our kernel is world-class at discrete industrial coordination. It masters energy-aware routing, shared task-pool prioritization, and long-horizon planning where the goal is distant and sparse. It turns "unpredictability" into a training advantage.
Where Challenges Remain
Currently, the tabular architecture is optimized for coordinating pairs. In scenarios requiring thousands of simultaneous agents in continuous, non-grid spaces, the system would require a transition to Deep RL to manage the "curse of dimensionality."
Contribution to the Frontier
AIDK contributes to the frontier of RL by demonstrating that Multi-Agent Coordination in long-horizon tasks doesn't require massive compute—it requires precise environmental design.
By focusing on Reward Hardening and Energy Constraints, I am providing a template for how RL should be applied to real robotics: with safety, transparency, and industrial efficiency at the core.